Entity file manager é um recurso que permite persistir entidades em arquivos estruturados. Ele foi desenvolvido com a finalidade de dar suporte à persistência de dados no BRCache. Ele basicamente é composto pelas classes EntityFileManager, EntityFile, EntityFileAccess e EntityFileTransactionManager.
1. EntityFileManager
A classe EntityFileManager provê todos os recursos necessários para a manipulação de entidades. Ela trabalha em conjunto com EntityFileAccess para armazenar as entidades no arquivo e EntityFileTransactionManager para manter a consistência.
Para cada operação de inserção, atualização e seleção, é necessário que sempre tenha uma transação explicita.
São providas somente instâncias da EntityFile associadas a uma transação. As operações executadas nela são delegadas ao EntityFileTransactionManager que faz as o necessárias para manter a consistência do arquivo.
2. EntityFile
A classe EntityFile provê recursos que permitem manipular um tipo específico de entidade. Com ela é possível inserir, atualizar, apagar e selecionar uma entidade. Ao inserir uma entidade, o EntityFile envia uma requisição ao EntityFileTransactionManager solicitando que a entidade seja incluída no arquivo. Depois de inserida, é obtida uma identificação única. A identificação indica a posição da entidade dentro do arquivo.
Na atualização, o EntityFile envia uma requisição ao EntityFileTransactionManager solicitando que ela seja atualizada no arquivo. Então ocorre seu bloqueio, atualização e posterior liberação após o fim da transação.
A exclusão de uma entidade é, em síntese, uma atualização. A operação vai depender do EntityFileAccess. Este pode apenas inserir um entidade vazia ou também mapear a lacuna para uma posterior inserção.
Na seleção, o EntityFile envia uma requisição ao EntityFileTransactionManager solicitando a entidade e ele devolve a entidade ou null que pode ser obtido diretamente do arquivo ou de um outro local temporário. O bloqueio nesse caso é opcional.
3. EntityFileTransactionManager
A classe EntityFileTransactionManager é responsável por manter a consistência dos arquivos após sua alteração. Ele recebe as requisições do EntityFile e as processa. A forma como o processamento de tais requisições é feita, vai depender da implementação utilizada.
O EntityFileTransactionManager pode gerar dois tipos de logs. O recoverylog que permite recuperar as transações após parada abrupta da aplicação e o binlog que tem a função de permitir a replicação das operações em outra aplicação.
Os dois logs possuem o seguinte formato:
****************************************************************
| | corpo | |
****************************************************************
| | | | |
| ml (8 bytes)| nt (8 bytes) | t (nt - nl - 8) | chk (8 bytes) |
| | | | |
****************************************************************
- ml: marcação da transação. Ele indica um novo registro e seu valor é o ponteiro obtido após sua leitura no arquivo;
- nt: apontamento para o próximo registro do log ou final do arquivo;
- t: dados da transação, tem o tamanho (nt-nl-8) bytes;
- chk: conjunto de 8 bytes usado para validar o corpo do registro.
Os dados da transação (t) tem o seguinte formato:
**********************************************************************
| | | | | | | |
| st | to | id | i | flg | ef | efd |
|(1 byte)|(8 bytes)|(8 bytes)|(1 bytes)|(1 bytes)|(1 bytes)|(n bytes)|
| | | | | | | |
**********************************************************************
- st: status da transação;
- to: timeout original da transação;
- id: identificação da transação;
- i: isolamento da transação;
- flg: flags que indicam se a transação foi confirmada, cancelada e iniciada;
- ef: indica a continuidade ou o fim da lista de EntityFile utilizados na transação. O valor -1 indica o final da lista;
- efd: dados do EntityFile manipulado na transação.
Os dados do EntityFile na transação tem o seguinte formato:
****************************************************************
| | | |
| cabeçalho | dados | eof |
| (n bytes) | (n bytes) |(n bytes)|
| | | |
****************************************************************
- cabeçalho: cabeçalho do EntityFile. O tamanho é o mesmo do cabeçalho original;
- dados: lista das entidades manipuladas na transação;
- eof: indicação do final do EntityFile. O tamanho é o mesmo do eof original.
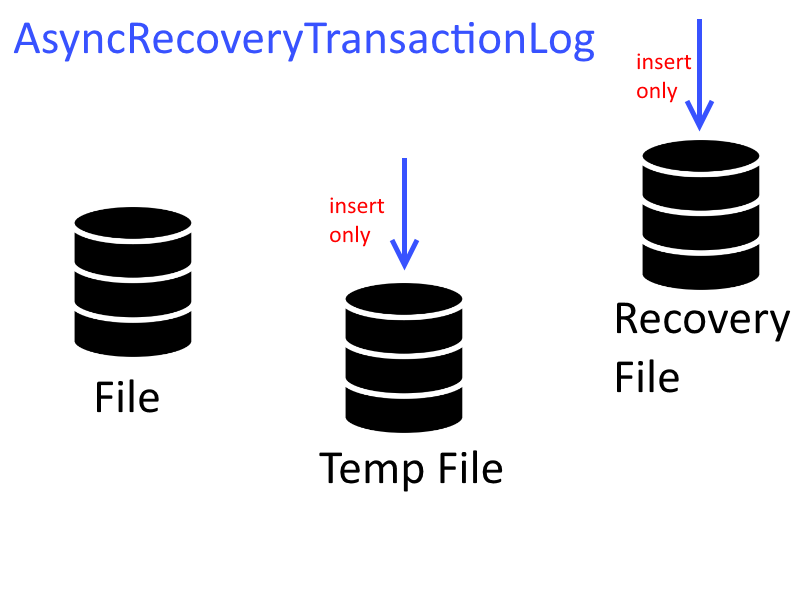
3.1 AsyncRecoveryTransactionLog
A classe AsyncRecoveryTransactionLog é a implementação padrão do recovery log. Permite que transações confirmadas possam ser efetivadas em paralelo com transações em execução. Também favorece a redução das operações de I/O, pois ele permite atualizações em lote. Todas as operações de inserção e atualização são executadas em um arquivo temporário num primeiro momento e depois em segundo plano no arquivo original.
Uma transação confirmada é gravada no arquivo recoverylogX e as alterações dela também são gravadas no arquivo temporário.
Quando o arquivo recoverylogX atinge o seu tamanho máximo, ele é fechado e enviado para um processo paralelo que aplica as alterações no arquivo original. O arquivo temporário é sincronizado com o arquivo original somente quando não houver transações ativas.
Em caso de parada abrupta da aplicação, o log de transação pode ser cortado na última transação válida. Isso é possível porque as transações são registradas de forma sequencial no arquivo e sua estrutura permite avaliar a integridade da transação. Este corte não ocorre de forma automática e precisa ser autorizado antes da aplicação ser iniciada. É possível definir como padrão o corte do arquivo de log.
4. EntityFileAccess
A classe EntityFileAccess provê recursos que permitem manipular diretamente o arquivo. Ele é responsável por gravar e ler os dados das entidades. A estrutura do arquivo é definida pelo EntityFileAccessHandler que codifica e decodifica o cabeçalho e as entidades em dados.